Talán észre sem veszi, hogy amikor beüti a navigációs rendszerbe, hogy hová szeretne menni az autójával, akkor az a lehetséges útvonalak közül a leggyorsabbat igyekszik kiválasztani, azaz prediktív (előrejelző) analitika segítségével megjósolja, hogy hogyan fog a leggyorsabban elérni a céljához. Hasonló módszer segít Önnek, amikor egy tavaszi reggelen az időjárás előrejelzést nézi a telefonján, hogy mennyire meleg ruhát húzzon, vagy kell-e vinnie esernyőt.
Az üzleti életben talán még fontosabb a hatékony előrejelzés, mert ennek segítségével csökkentheti a költségeit, és növelheti a működési biztonságot. Ha látja előre a várható ingadozást a cashflow-ban, akkor előre fel tud rá készülni. Ha meg tudja jósolni a jövőbeli rendeléseket, akkor optimális szinten tudja tartani a készletet. Ha előre érzékeli, hogy egy vevője elhagyni készül Önt, akkor oda tud küldeni egy értékesítőt, aki egy jó akcióval vagy a vevő problémájának kezelésével visszahozza a rendeléseket.
A mesterséges intelligencia prediktív analitika nevű területe új, de mivel óriási mértékben tudja befolyásolni azon cégek profitját, akik ki tudják használni, ezért futótűzként terjed. Használják:
- az online marketingben, hogyan tudják hatékonyabbá tenni a hirdetéseket,
- a közösségi médiában,
- a felhasználói élmény növelésében,
- csalás és hiba előrejelzésében,
- pénzügyi döntések előkészítésében,
- a tőzsdén és a Forex-en,
- kockázatelemzésben,
- HR-ben a felvételnél és a munkatársak motivációjának megtartásánál,
- készlettervezésben,
- gyártási folyamatok optimalizálásában,
- és még számtalan egyéb helyen.
Big Data, prediktív analitika és üzleti intelligencia a cégek életében
Egyre több szervezet tárolja adatait digitális formátumban, percről-percre nő a tárolt adatok mennyisége az interneten és a közösségi médiában, és egyre több okos eszköz csatlakozik rá az internetre, adatbázisokra, és rögzít különféle információkat.
A rendelkezésre álló adatok mennyisége exponenciális mértékben növekszik, és ezen adatok tartalmazzák azon szabályszerűségeket, amik alapján hatékonyan jósolható a jövő, azaz a Big Data korában – ha nem is exponenciálisan, de – egyre jobban működik a prediktív analitika a gyakorlatban. Természetesen ehhez az is hozzájárul, hogy a prediktív analitikát segítő matematikai módszerek új tudománya is fejlődik, de a matekos résszel nem szeretném terhelni ebben a cikkben.
Az, hogy a sok adatból hogyan lehet kinyerni az információt az az üzleti intelligencia rendszerek területe (az üzleti intelligencia (angolul Business Intelligence, röviden BI) gyűjtőfogalom; magában foglalja azokat az alkalmazásokat, legjobb gyakorlatokat, eszközöket, amelyek lehetővé teszik, hogy megszerezhessünk és felhasználhassunk olyan információkat, amelyek fontosak ahhoz, hogy az üzleti döntéseket és így az üzleti teljesítményt javítsuk), és ezért természetes fejlődési irány az, hogy a prediktív analitika funkció leginkább az üzleti intelligencia rendszerek alkalmazásához áll legközelebb, és számos BI rendszer használ is különböző eljárásokat a prediktív analitikára.
Egyszerű azonban belátni, hogy amennyire segít egy ilyen rendszer a hatékony és helyes előrejelzésével, annyira tud rombolni is, ha nem jól működik (gondoljon arra, hogy napfényes időt jósolnak, eközben szétázik az esőben egy fontos üzleti tárgyalásra menet), ezért nagyon fontos, hogy a lehető legjobb módszert alkalmazza az üzleti jövője előrejelzésére. Fontos tehát tisztában lenni azzal, hogy az egyes üzleti intelligencia eszközök milyen mesterséges intelligencia módszereket használnak prediktív analitikára, és azt is, hogy az Ön adatai esetén melyik lehet a leghatékonyabb eljárás a jövő előrejelzésére.
Adatelemzés és prediktív analitika háttere
Mielőtt még a prediktív analitika mélységeibe hatolnánk, fontos tisztában lennie az alapvető big data és adat-analitikai fogalmakkal. Az adatok feldolgozása klasszikusan a matematika, azon belül a matematikai statisztika területe, ami még akkor is megkerülhetetlen, ha manapság már a számítógépek átvették az uralmat az adatfeldolgozás és az adatelemzés felett.
Talán hallott már a hipotézisvizsgálatról, ami a statisztikai módszerek alapeleme. Ilyenkor feltételezünk valamit és vizsgáljuk, hogy az mennyire igaz. Ez egyfajta célkitűzés (objective), ami nagyon fontos a saját adatai elemzésében is. Vagyis fel kell tennie helyesen a kérdést, hogy pontosan mire kíváncsi:
- Melyik termékemen van a legtöbb profitom?
- Szezonális az értékesítésem?
- Mely dolgozóim dolgoznak a legtöbbet, és kik termelik meg a legtöbb értéket?
Ezekre a kérdésekre adott lehetséges válaszokat lehet statisztikailag elemezni. Mindemellett el kell döntenie, hogy mit és hogyan mér. Mivel valószínűleg Ön és munkatársai ismerik legjobban a saját folyamatait, ezért ezt Önnek kell kitalálnia, abban tapasztalt tanácsadók tudnak segíteni, hogy hogyan kell gyűjtenie ehhez adatot. A következő lépés az adattisztítás, ami az ismétlődő és hibás adatok kiszűrését jelenti. Ez a lépés olyan kulcsfontosságú, hogy néhány üzleti intelligencia rendszer beépítetten támogatja pl. egy kiugró érték (outlier) vizsgálattal.
Ha ezeken a lépéseken túl van, akkor jön az adatanalízis, ami az üzleti intelligencia rendszerek igazi vadászterülete. Minden BI tudja az adatvizualizációt, amikor az adatait színes grafikonok (charts) formájában jeleníti meg, és segítenek a gyors döntésben vagy az eredmények prezentálásában egy találkozón. A másik lehetséges adatanalitikai módszer az értelmező (explanatory) adatelemzés, amikor az eszköz lehetőséget ad arra, hogy az adatok mélyére ásson, és megtalálja az összefüggéseket. Ilyen eszköz például a grafikonoknál a lefúrás (drill down) lehetősége, de a pivot tábla is egy tipikus értelmező eszköz.
Talán a legérdekesebb (és a prediktív analitika irányába mutató) adatelemzési módszer a leíró statisztikai elemzés (descriptive statistics), ami a vizsgált adatok karakterisztikáját vagy tulajdonságait hivatott leírni (pl. növekszik vagy csökken, homogén vagy diverz, melyik termékcsoport értékesítése nagyobb átlagosan). Ide tartoznak a jól ismert statisztikai mérőszámok: átlag, szórás, medián, variancia stb., és ezek mind vizuálisan, mind pedig értelmező táblázatokban is megtálalhatók. Mivel feltételezzük, hogy a vizsgált adatokon mért jellemzők kiterjeszthetők a teljes adattömegre és így a jövőben gyűjtendő adatokra is, ez az a módszer, ami átvezet minket a prediktív analitikához.
Prediktív analitika
A prediktív analitika a leíró, deszkriptív analitikából fejlődött ki, amiről az előbbi bekezdésben írtam. A leíró elemzés képes feltárni egy idősorról (az idősor az egymást követő időpontokhoz vagy időszakokhoz tartozó adatok sora, amit egy kétdimenziós grafikonon úgy tudunk ábrázolni, hogy a vízszintes tengely az idő és a függőleges tengelyen vannak az adatok), hogy növekvő vagy csökkenő trend jellemzi, és ha egy mért adat az elmúlt két évben minden nap növekedett, akkor nagy biztonsággal mondhatjuk, hogy jövő hétfőn is növekedni fog (csak az adattudós és matematikus olvasóknak írom, hogy milyen szép lenne itt egy kicsit a Bayes-tételről és a feltételes valószínűségről is írni) – és el is érkeztünk a prediktív elemzéshez.
A prediktív analízis az esetek többségében ennél sokkal bonyolultabb, és a deszkriptív elemzés sokszor nem talál törvényszerűségeket a vizsgált adathalmazban, az előrejelzést viszont meg kell tenni. Az ilyen esetekben sokszor már ún. algoritmusokat használunk, amik általában több lépésből állnak, amíg az utolsó lépésben a kívánt eredményhez vezetnek.
A prediktív analízis szokásos módszere, hogy az adatok egy jelentős részét elkülöníti (ez általában 80%) és ezeken az adatokon “tanítja” az algoritmust, majd a fennmaradó részén az adatoknak (általában 20%) teszteli az algoritmus hatékonyságát. Mivel ezek az algoritmusok a módszer során “megtanulják” az adathalmaz tulajdonságait, tanuló algoritmusoknak nevezzük őket, az informatikában ezt hívják machine learningnek (gépi tanulás), és sok helyen a mesterséges intelligencia elnevezés mögött valójában a machine learning van.
Eddig azok a szervezetek, akik komolyan akartak foglalkozni a prediktív analitikával, adattudóst vettek fel (vagy ilyen részleget létesítettek), aki Python-ban, R program-nyelvben vagy egyéb eszközrendszerben lekódolta a szükséges elemző eszközöket. Az alábbiakban azonban láthatja, hogy az üzleti intelligencia rendszerek olyan mértékben fejlődnek, hogy nincs szüksége saját tudósra ahhoz, hogy az üzleti adataiból meg tudja jósolni a jövőt.
A prediktív analitika után a következő lépcsőfok az ún. előíró vagy preszkriptív analitika, ami nemcsak a jövőt jósolja meg, hanem abban is segítséget nyújt, hogy a jövőbeli várható események fényében mit kell tennünk, hogy a kezdetben rögzített célkitűzésünket elérjük. Erről a technikáról az utolsó fejezetben lesz szó.
A következő részben igyekszem egy általános áttekintést adni arról, hogy milyen módszereket használnak jelenleg a piacon lévő üzleti intelligencia rendszerekben, és melyiket mennyire egyszerű használni. Az egyszerű használat azért fontos, mert az önkiszolgáló BI. már elterjedt és régóta központi kérdés ezeknél a rendszereknél, de az önkiszolgálásról előszeretettel elfeledkeznek a rendszer tervezői, amikor összetettebb prediktív elemzéseket kell elvégezni. Tehát az alábbi elemzésből eldöntheti, hogy mely módszerek a leghatékonyabbak az üzleti adatai elemzésére, és melyik BI eszköz használatához van elég tudás és szakértelem a cégében, azaz mit tud viszonylag kis TCO-val használatba venni.
Prediktív analitikai módszerek
1. Trendvonal vagy regresszió
Ez a legegyszerűbb, ezáltal a legelterjedtebb prediktív eszköz, és így az üzleti intelligencia szoftverek széles körében elérhető, de már az Excel is tudja. Ha grafikusan felrajzolja az adatait vagy ábrázolja őket pl. egy idősor esetén, akkor kézzel is meg tudja rajzolni a trendvonalat, ahogyan azt az alábbi ábra szemlélteti a Tableau BI rendszer esetén.
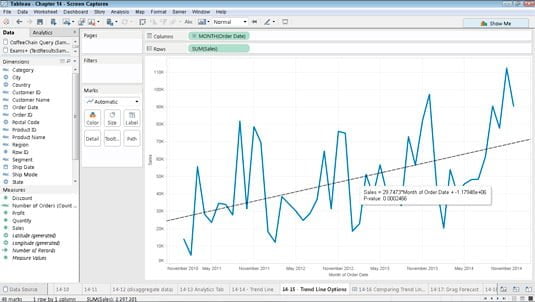
A trendvonal funkciót általában nagyon egyszerű használni, hiszen az adatok adottak, a szoftver pedig egy gombnyomásra megcsinálja az illesztést. A legtöbb rendszernél szükséges megadni a használt regresszió típusát (lásd alább), amihez azért picit érteni kell a statisztikához, de ez az ismeret tapasztalati úton is megszerezhető.
A lineáris regresszió esetén gyakorlatilag egy egyenest próbálunk ráilleszteni a grafikonra, amint az a fenti, Tableau-ból kivágott ábrán is látszik. És az is látszik az ábrán, hogy ez nem a legjobban illeszkedik, ezért a gyakorlatban, amikor az adataink nem folyamatos függvény kimenetei, hanem különállók (diszkrét változók) a logisztikus regressziót szoktuk használni, ahol a kimenetek valószínűségi értékek, azaz ebben az esetben egy esemény bekövetkeztének valószínűségét kapjuk eredményül. (Itt van az a pont, ahol érzem, hogy a nem matekos olvasót le is fárasztottam kicsit ezzel a logisztikus regresszió magyarázattal, ezért nem akarom terhelni egyéb kimondhatatlan regressziós technikák (Probit, Polinomial, Ridge, Lasso, ElasticNet stb.) kifejtésével.) A regresszióból elég, ha annyit megjegyez, hogy ilyenkor adatsorra illesztünk görbéket (az egyenes is egyfajta görbe) és hogy a statisztika ezen területe nagyon gazdag.
A legtöbb üzleti intelligencia rendszer megáll a lineáris és logisztikus regresszió használatánál, ami nemcsak azt jelenti, hogy bonyolultabb regressziós technikák nem elérhetők a szoftverekben, hanem azt is, hogy a további pontokban tárgyalt fejlettebb módszereket sem lehet használni beépítetten a legtöbbjükben (köztük a PowerBI, a Sisense, a Tableau, a Qlik, a Looker, a Domo sem támogatja ezeket).
Azaz a piacvezető üzleti intelligencia rendszerek többsége megáll a trendvonal és regressziós módszerek szintjén, és ezeken kívül semmi mást nem lehet használni a menüből. Ezért írtam korábban, hogy eddig azokban a cégekben, ahol komolyan akartak foglalkozni a big datával, mesterséges intelligenciával és prediktív elemzéssel, mindig szükség volt programozóra, adattudósra, aki Python vagy R programnyelvben kifejlesztette a szükséges algoritmusokat, amit azután már tudtak használni az adott üzleti intelligencia rendszerben.
Ráadásul azoknál az üzleti intelligencia rendszereknél, amelyek igyekeznek egyszerűvé tenni ennek a funkciónak a használatát (pl. Tableau), egyetlen regressziót (általában logisztikus típusút) használnak minden adat illesztésére, ami könnyűvé teszi ugyan a használatot, de nagyon pontatlanná teszi az előrejelzéseket, míg azok az eszközök (pl. a PowerBI Forecast modulja), amelyek viszonylag jól paraméterezhetően jobb eredményeket adnak, csak komoly statisztikai tudás birtokában használhatók biztonsággal.
A trendvonal előnye a számítási gyorsasága, egyszerűsége és szemléletessége, nagy hátránya azonban, hogy komplexebb esetekben rossz előrejelzéseket ad. Ha csak viszonylag kevés adata van (néhány ezer) és elegendő a trendvonal meghatározása az Ön esetében, akkor én az Excel trendvonal megoldását ajánlom, amiről itt talál részletes leírást: https://www.excel-easy.com/examples/trendline.html
A Dyntell Bi-ban lévő Ensemble rendszerben (lásd később) egy logisztikus regresszión alapuló algoritmus található, a Prophet, amelyet Facebook-os fejlesztők kezdtek el programozni, nyílt forráskódúvá tették és a Dyntell továbbfejlesztette. A Prophet nagyon jó konszenzus az egyszerűség és a hatékony előrejelzés között, nagy előnye, hogy jól detektálja az idősorok szezonalitását is.
Összefoglaló: TRENDVONAL ÉS REGRESSZIÓ
Önkiszolgáló szint: Magas
Előnyök: Gyors válaszidő, kis számítási igény, elterjedt módszer.
Hátrányok: Közepes előrejelzési hatékonyság és a big data adatbázisokon rosszul működik.
2. Mozgóátlag
Az Excelben ez is csak egy trendvonal típus (mint ahogyan azt az Excel tutorialban láthatta), de kifinomult használata miatt sokkal összetettebb, sőt, a magam részéről olykor erősebb eszköznek tartom a hagyományos regressziónál. A mozgóátlagot gyakorta használják a deviza- (Forex) vagy tőzsdei piacok elemzésekor (kedvencem a Double Bollinger Band), mi több, megbízható működése révén üzleti idősorok vizsgálatakor is bátran támaszkodhatunk rá.
A legszélesebb körben alkalmazott mozgóátlag módszer valószínűleg az ARIMA. Az algoritmus mögötti matematikáról itt olvashat bővebben:
(https://en.wikipedia.org/wiki/Autoregressive_integrated_moving_average)
Az ARIMA paraméterei a ‘p’, ‘q’, és ‘d’, melyek közül:
- ‘p’ – az autoregresszív kifejezések száma
- ‘d’ – a stacionáriussághoz szükséges (nem szezonális) különbségek száma
- ‘q’ – a késleltetett előrejelzési hibák száma a predikciós egyenletben.
Az adattudósok különböző paraméter-beállításokat tesztelnek, hogy megtalálják a legmegfelelőbb előrejelzést az adott adatkészlethez. A Dyntell Bi-ban az automatizált folyamat sok beállítási permutációt tesztel, és megtanulja a legjobb módszert egy adott idősor jövőbeli használatához.
A kisebb adatsorokon jól működnek a különféle mozgóátlag módszerek, noha a pontosság épp csökken az adatmennyiség növekedésével.
Ha még nem vesztette el a lelkesedését, úgy kipróbálhatja az ARIMA-t például a SAS BI-ban. Játsszon a p, d, q paraméterek beállításaival, hogy még mélyebben megismerje a mozgóátlagot.
Összefoglaló: MOZGÓÁTLAG
Önkiszolgáló szint: Közepes
Előnyök: Könnyen érthető, gyors válaszidő, jó becslési minőség a megfelelő beállítások esetén.
Hátrányok: Az adatállomány méretének növekedésével (big data) csökken az előrejelzés pontossága.
3. Neuronhálózat
A mesterséges neurális hálózatok az emberi idegrendszert és az agyat modellező statisztikai algoritmusok. Nagy előnyük, hogy ezek a rendszerek könnyen megoldják azokat a komplex problémákat, amelyek kihívást jelentenek a hagyományos algoritmusok számára, de egy ember számára egyszerű feladatnak számítanak (pl. arcfelismerés, természetes nyelvek feldolgozása).
Kedvenc példám a kézzel írott karakterek felismerése. Képzelje el, hogy a kézzel írt számot egy kockás füzetbe írja, és kiszínezi feketére azokat a kockákat, ahová a rajzolt szám vonala esik vagy amelyik kockát érinti. Így a kézzel írt számot átalakítja fekete és fehér kockákká, hogy számolni is tudjunk velük jelöljük ‘1’-el “pixeleket”, és ‘0’-val a fehér “pixeleket”. Ily módon a kézzel írt betűk képeit 1-esekkel és 0-kkal rendezett sorokba konvertálja.
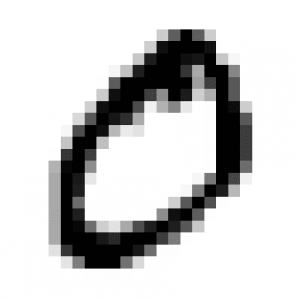
Ezt követően tanítanunk kell a hálózatot, azaz megmondani a gépnek, hogy az adott kép milyen betűt jelent. Ehhez kell egy ember, aki pl. megmondja: „Ez a számsor egy ‘o’ betű.” A neurális hálózat egy speciális függvénnyel kiszámítja a képhez rendelt számsorból a kép “energiaállapotát”, vagyis egy számot, ami a képet jellemzi. (A statisztikai számítás módszere a cikk tárgykörén kívül esik.) A tanulási mechanizmus azt jelenti, hogy a neurális hálózat ezt az energiaállapotot az ‘o’ betűs polcon helyezi el a képzeletbeli polcok közül (mivel azt mondta neki a tanító ember, hogy ez az ‘o’ betű). Több tucat különböző kézzel írott ‘o’-t kell megtanítani a neurális hálónak, és minden alkalommal, amikor ‘o’-ként azonosítjuk a képet, az algoritmus kiszámítja az energiaállapotot, majd az „o-polcra” helyezi azt. Természetesen más betűkhöz más polcok tartoznak, így a neurális hálózat képes megtanulni az egész ábécét.
És itt jön a trükk: amikor a neurális hálónak mutatunk egy új, kézzel írott ‘o’-t, melyet korábban még sosem látott, kiszámítja a kép energiaállapotát, majd ez alapján megtalálja az ehhez megfelelő polcot, ami az ‘o’ polc lesz és a felismert ‘o’ karakterrel válaszol.
A modern karakterfelismerő rendszerek már másképpen működnek, de ez egy kiváló példa a neurális hálózatok lényegének megértésére.
Hasonlóképp, a neurális hálózatok képesek megtanulni az idősorok jellegzetességeit, melyek felhasználhatók egy görbe jövőbeli pontjainak előrejelzésére. Ezekben az esetekben általában felügyelet nélküli hálózatokat használunk, ahol az algoritmusok emberi segítség nélkül is tudnak tanulni.
Ön már biztosan rájött, hogy ezen algoritmusok használatához mélyebb statisztikai tudásra van szükség. Egy Big Data rendszerben beállíthatja a hálózat méretét és összetettségét, megváltoztathatja az „energia” függvényt és kísérletezhet a neuronhálóval, de a használata sok tapasztalatot és komoly háttértudást igényel. A neuronhálózatot tesztelheti többek közt a Rapidminerben, ami remek eszköz, de egy azok közül, ami komoly adattudósi hátteret igényel.
A Dyntell Bi rendszerében a neurális hálózatok alkalmazása el van rejtve a felhasználók elől. A Dyntell Bi az idősorok statisztikai jellemzői alapján automatikusan meghatározza az alkalmazandó neurális hálózatok paramétereit, ami azután bekerül egy komplex rendszerbe, és hozzájárul a hatékonyabb előrejelzéshez.
Összefoglaló: NEURÁLIS HÁLÓK
Önkiszolgáló szint: alacsony
Előnyök: Jól alkalmazható osztályozási problémákra
Hátrányok: Előzetes tudást igényel a használata
4. Mélytanulás (deep learning)
A mesterséges neurális hálózat szerkezete olyan csomópontokból áll, melyek egymáshoz kapcsolódnak.
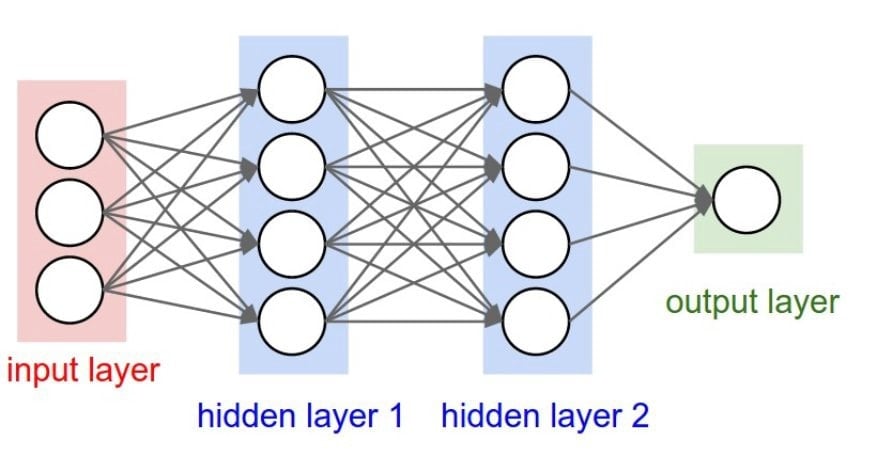
Egyes csomópontok vagy neuronok az ‘o’ karakter képének (a fenti példában) azonosításáért felelnek, ezek a neuronok a bemeneti rétegben vannak. Az energiaállapot kiszámítása néha összetettebb és több csomópontot igényel. Ezek egy vagy több rejtett rétegbe vannak rendezve, és a neurális hálózatok a kimeneti rétegen keresztül adják vissza az eredményt (amely szintén több neuront is tartalmazhat).
Vegye észre, hogy ez a folyamat az információ egyfajta tömörítésének tekinthető: egy képet tömöríthetünk egy energiaállapotba.
A mélytanulás abból a kissé őrült ötletből származik, hogy a rejtett rétegbe tömörített információt betesszük egy másik neurális hálózat bemeneti rétegébe (beágyazott neurális háló), majd a másik neuronháló rejtett rétegét egy harmadik neurális hálóba tesszük bemeneti rétegként. Így tömörítjük újra és újra az információt egyre tovább.
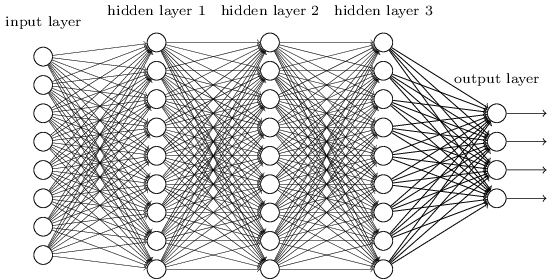
Ebből egy zűrzavarnak kellene kijönnie, de a helyzet az, hogy remekül működik. Mélytanuló (deep learning) hálózatoknak nevezzük őket, és rendkívül hatékonyak nagy mennyiségű adatokon, big data adatbázisokon. Ezek az algoritmusok már joggal nevezhetők mesterséges intelligenciának.
Az alábbi kép szemlélteti a mélytanuló hálózatok hatékonyságát a hagyományos algoritmusokkal szemben egy olyan világban, ahol az adatok mennyisége exponenciálisan növekszik.
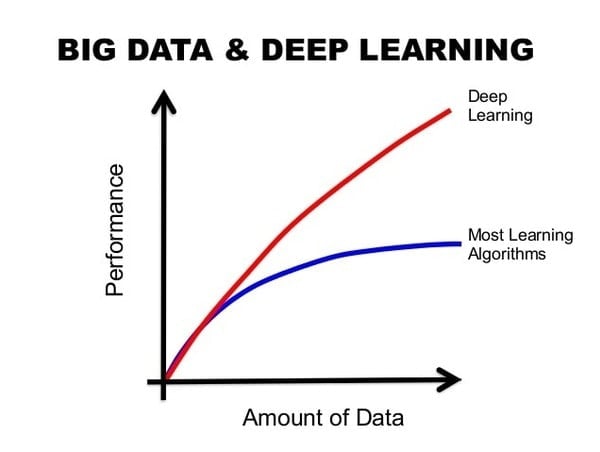 Forrás: https://image.slidesharecdn.com/dominodatasciencepopupseattledeeplearningusecases-151013134409-lva1-app6892/95/deep-learning-use-cases-data-science-popup-seattle-7-638.jpg?cb=144623097
Forrás: https://image.slidesharecdn.com/dominodatasciencepopupseattledeeplearningusecases-151013134409-lva1-app6892/95/deep-learning-use-cases-data-science-popup-seattle-7-638.jpg?cb=144623097
Másik előnyük az automatikus “feature extraction”, ami azt jelenti, hogy nincs szükség emberi erőforrásra a képek vagy adatok címkézéséhez. Fontos tulajdonság ez, hiszen mialatt az adatmennyiség exponenciálisan növekszik, addig mindezen információ feldolgozásához erőforrás is szükséges. Szerencsére a mélytanuló hálózatok megoldják ezt a problémát és alkalmazásuk egyre szélesebb körben terjed.
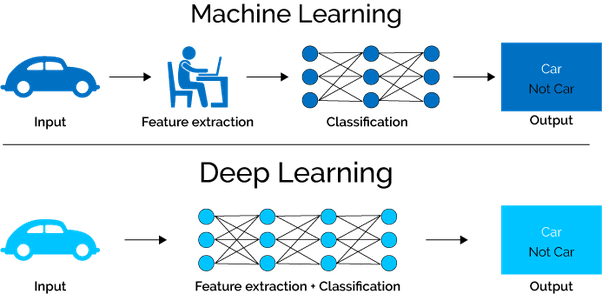
Forrás: https://content-static.upwork.com/blog/uploads/sites/3/2017/06/27095812/image-16.png
Felépíteni és működtetni egy mélytanulási rendszert valódi kihívás, ráadásul ha nincs elég adata, úgy várhatóan meg sem éri az erőfeszítést, hiszen az algoritmus valódi ereje épp abban rejlik, hogy big data mennyiségű adatok alapján adjon minél pontosabb előrejelzéseket.
A mélytanulás használatához szüksége lesz egy speciális GPU szerverre.
Ha adattudós, úgy tegyen egy próbát a mélytanulásra pl.: a H2O.ai-ban, a KNIME-ben, vagy a MATLAB-ban, de saját hálózatát is felépítheti Pythonban a Keras keretrendszer használatával.
A Dyntell Bi-ban is van természetesen deep learning algoritmus, de ennek paraméterezése is önműködően történik az adatok statisztikai paraméterei alapján.
Összefoglaló: DEEP LEARNING
Önkiszolgáló szint: Egy mélytanuló rendszer felépítéséhez adattudósra van szükséged
Előnyök: Automata “featue extraction” és a legjobb eszköz az óriási adattömegek kezelésére
Hátrányok: GPU szerverre van szükség
5. Ensemble rendszer
Az Ensemble rendszer több tanuló algoritmusból tevődik össze, ahol a kimenetet a tagok súlyozott eredményei adják. Ez a módszer jobb előrejelzést ad, mint amit kinyerhetnénk a részeiből, a tanuló algoritmus összetevőkből. Az Ensemble példa a konszenzus keresésre, hiszen számunkra fontos kérdésekben mi is mindig kikérjük mások véleményét, úgy az Ensemble rendszer is több „véleményt” ütköztet a legpontosabb előrejelzés érdekében.
További információt itt talál: http://users.rowan.edu/~polikar/RESEARCH/PUBLICATIONS/csm06.pdf
Noha többek közt RapidMinerben is felépíthet egy Ensemble rendszert, de ahhoz, hogy az üzleti adataira is előrejelzéseket tudjon vele tenni, mindenképp szüksége lesz egy adattudós csapatra, adattudós alkalmazás fejlesztőkkel, és legalább egy ‘fekete öves’ matematikusra.
A Dyntell Bi Ensemble rendszere két szerver segítségével készít előrejelzéseket: míg az egyik szerveren klasszikus algoritmusok futnak, addig a másik szerveren neuronhálózatok és mélytanuló algoritmusok. Ezáltal pontosabb előrejelzéseket tesz, mint a hagyományos algoritmusok, és egyaránt működik big datán és kis mennyiségű adatokon is. Ez egy hatékony módja az üzleti előrejelzéseknek, amikor nem feltétlenül rendelkezünk nagy adatmennyiséggel, de a vezetőség hajszálpontos eredményeket vár.
Összefoglaló: ENSEMBLE RENDSZER
Önkiszolgáló szint: szüksége van egy adattudós csapatra a létrehozásához
Előnyök: az Ensemble rendszer egyesíti magában az összes korábban leírt algoritmus hatékonyságát
Hátrányok: szerver oldalon nagy teljesítményre van szükségünk a használathoz, míg a válaszidő igen lassú
6. Korreláló idősorok
Adataink jövője vajon tényleg csak az adott adathalmaz múltbéli mintázataitól függ? A részvényárfolyamok esetén biztosan nem. Ha valami olyan történik a világban, ami összefügg a részvényekkel, akkor az árak rögtön megváltoznak. Viszont ha valóban befolyásolják a külső tényezők a részvény-árfolyamokat, akkor képesek kihatni egy cég eladási számaira is? És ha vizsgáljuk ezen külső tényezőkből származó adatokat, akkor az üzleti adatai jövőjét is képesek vagyunk pontosabban előrejelezni?
Mielőtt választ adnék ezekre a kérdésekre, nézzük, hogyan váltak nagy adatbázisok a gépi tanulás fő segítőjévé a mesterséges intelligencia rövid történelme alatt.
A WordNet (https://wordnet.princeton.edu/) egy angol nyelvű lexikai adatbázis (több mint 150.000 szóval). A WordNet synset-eket, szinoníma készleteket használ ahhoz, hogy körülírja egy szó jelentését. Ez az adatbázis igen hasznos, ha szövegelemzés témában fejleszt valaki mesterségesen intelligens szoftvert.
Az ImageNet (http://www.image-net.org/) a WordNet ötletéből származik, viszont ez egy hatalmas képadatbázis (több mint 14 millió képpel). A cél viszont hasonlóan a mesterséges intelligencia programok segítése, elsősorban képfelismerő szoftvereket fejlesztők általi használatra tervezve.
A TimeNet (http://timenet.cloud/) az idősorok adatbázisa, gazdasági és földrajzi adatokat tárol, naponta frissítve azokat. Az itt tárolt adatokkal külső gazdasági folyamatok írhatók le, egyúttal azon törekvéseinket is támogatja, hogy korrelációt találjunk ezen külső tényezők és egy adott vállalat adatai között. Játszhat a TimeNettel, hogy kipróbálja, talál-e korrelációkat a feltöltött idősorok között. Azonban ha a saját adatait szeretné összevetni ezekkel vagy épp más idősorokkal, szüksége lesz a Dyntell Bi rendszer telepítésére.
A TimeNet a klasszikus korreláció fogalmat és a saját korrelációs módszerét is használja. A klasszikus korreláció hasonlóságot keres a görbék alakjában (saját adataival itt tud játszani: https://www.mathsisfun.com/data/correlation-calculator.html), de a TimeNet saját fejlesztésű korrelációja az idősorok viselkedésében keres hasonlóságot. A viselkedések összehasonlításához a TimeNet meghatározza egy görbe trend-váltó pontjait (lokális minimumok és maximumok), így ha egy másik idősornak is időben közel található trend-váltó pontja, úgy feltételezhető kapcsolat a két idősor között.
A korreláció nem mindig jelent ok-okozati összefüggést. Ugyanígy jelentheti, hogy a két adatállomány hátterében ugyanaz a matematikai törvény érvényesül. Kissé morbid, ugyanakkor vicces példákat találhat itt is az erősen korreláló, de egymással nem ok-okozati kapcsolatban lévő idősorokra: http://www.tylervigen.com/spurious-correlations
Noha az idősorok közötti korreláció koncepciót a tőzsdén nagyon is alkalmazzák, nincs szabvány üzleti szoftver példa a saját adatai és korreláló idősorok elemzésére (a Dyntell Bi kivételével). Például a Qlik segítségével elérhető a DataMarket adatbázisa (https://www.qlik.com/us/products/qlik-data-market), de nincs olyan eszköz a Qlik-ben, mellyel elemezhető lenne az adatok közti korreláció. Ha mélyebbre akar ásni, úgy számtalan tudományos cikk foglalkozik ezzel a témával (pl. https://ieeexplore.ieee.org/document/6222660)
Összefoglaló: KORRELÁLÓ IDŐSOROK
Önkiszolgáló szint: magas (TimeNet.cloud)
Előnyök: új változót hozhatunk az előrejelzésbe: mely függ a külső tényezőktől
Hátrányok: külső adatkészleteket kell kezelnie ahhoz, hogy korrelációt találjon az adataival
7. Dyntell Bi “TimeNet Deep Prediction”
A TimeNet mély előrejelzés módszere a prediktív analitika fenti 6 szintjét egyesíti, néhány további funkciót adva a folyamathoz. Ez a jelenleg elérhető legkiterjedtebb és legegyszerűbben használható előrejelző eszköz, ami ráadásul működik a kis mennyiségű és a nagy mennyiségű adatokon is.
A módszer elérhető a Dyntell Bi-ból, és használata egyszerű. Ha van egy olyan diagramja, ami idősort ábrázol (vagyis a vízszintes tengelyen az idő van ábrázolva), és elindítja egy kattintással az előrejelzési folyamatot, a Dyntell Bi elküldi az idősor adatait a felhőbe. Itt a Dyntell GPU kiszolgáló klaszter fogadja és indul a predikció. Az elemzés időt vesz igénybe, és amíg várunk a válaszra, természetesen az üzleti intelligencia szoftver is használható, és figyelmeztetést kapunk, ha az előrejelzés készen van, a rendszer visszakapta a prediktált adatokat.
De mi történik a háttérben?
A felhőben az első lépés a kapott adatok jellemzése: egy neuronhálózat meghatározza az adatok fő statisztikai tulajdonságait, vagyis a megfelelő osztályba sorolja az idősort azok alapján. A második lépés a kiugró értékek (outlierek) kiszűrése, ha vannak ilyenek. Az outlierek hibákat is jelenthetnek, de az is lehet, hogy hozzá tartoznak a valós adatokhoz (utóbbira példa egy értékesítési idősor esetén, ha van egy nap, amikor egy nagy projekt kezdődik, és 100-szor több értékesítés történt), de mindkét esetben hibás eredményeket hozhat létre, ezért kiszűrjük azokat, amik zavarhatják a megfelelő predikciót.
A következő lépés a TimeNet adatbázisban található adatok és a kapott üzleti adatok közötti korreláció elemzése. Ha a Dyntell Bi 85%-os vagy nagyobb korrelációt (klasszikus korrelációt vagy trend-korrelációt) talál a TimeNet idősorok között, akkor a Dyntell Bi hozzáköti a korreláló adatokat a kapott adatokhoz, és a folyamat következő lépéseiben figyelembe veszik a korreláló idősorokat is.
A fenti tapasztalatok alapján a Dyntell Bi beállítja az Ensemble rendszer paramétereit. Ezután az Ensemble számítás egyidejűleg indul el egy hagyományos kiszolgálófürtön, és egy másik GPU szerver-klaszteren.
Az első klaszter „klasszikus algoritmusokat” (regressziókat és testreszabott ARIMA-kat) futtat – ezeknek a funkcióknak kis mennyiségű adatra van szükségük jó előrejelzések létrehozásához, de előrejelzéseik nem teljesen pontosak. A másik klaszteren neurális hálók és mély tanulási algoritmusok futnak, amelyek nagyon nagy adatállományokat képesek feldolgozni (millió vagy milliárd adatpont), és ha elegendő adata van, akkor itt pontosabb előrejelzéseket kaphat.
Mivel az üzleti adatállományok általában kicsik, de nagy pontosságot igényelnek, mindkét módszertan integrálva van az Ensemble rendszerbe.
A folyamat végén az előkonfigurált súlyok alapján az Ensemble rendszer meghatározza a kimenetet: a szükséges számú előre jelzett adatpontot, és visszaadja ezeket a helyi Dyntell Bi rendszerbe. A megjelenítés után a rendszer figyelmezteti a felhasználót, hogy az előrejelzés befejeződött.
Összefoglaló: DYNTELL Bi TIMENET DEEP PREDICTION
Önkiszolgáló szint: Magas
Előnyök: Egyesíti a prediktív elemzés további 6 szintjét
Hátrányok: Nagy feldolgozási teljesítményre van szükség (klasszikus és GPU szerverek)
Előíró (preszkriptív) elemzés
Az előíró elemzés arra a kérdésre ad választ, hogy “mit tehetünk?” azért hogy meggátoljunk egy problémát vagy kihasználjunk egy lehetőséget, ami a célunk felé vezet minket.
A preszkriptív elemzés a prediktív elemzés után a következő lépcső. Ez a módszer nem csak a jövőt jósolja, hanem még abban is segít, hogy mit kell tennünk a jövőben, hogy a kívánt eredményt elérjük. Ha lehetséges, akkor a megfelelő lépéseket (pl. egy üzenet elküldése, adat visszaírása az ügyviteli rendszerbe) meg is teszi helyettünk, és így a folyamatot is automatizálhatja, hogy proaktívan kezelje üzleti problémáit – kihasználjon egy üzleti lehetőséget, vagy megakadályozzon a problémát.
Az előíró elemzést riasztásokkal lehet kezelni, ezért a kifinomult riasztórendszer vagy munkafolyamat-rendszer elengedhetetlen a modern üzleti intelligencia szoftverben.
A preszkriptív elemzés erősségének bemutatásához két esettanulmányt szeretnék megosztani.
1. Costa Coffee
A Costa kávézó lánc üzleteiben valószínűleg már Ön is sok kávét ivott, legközelebb gondoljon arra, hogy itt a Dyntell Bi elemezi a kávézók összesített adatait. A prediktív elemzés az üzletek jövőbeli tranzakciószámát mutatja üzletenként. Ez segít a Costa-nak abban, hogy hatékonyan kezelje a humán erőforrásait, és éppen a megfelelő számú barista, valamint kiszolgáló legyen a shopban, továbbá figyelmezteti a menedzsmentet, ha váratlan esemény fordulhat elő. Costa nem használja a TimeNet-et, de az algoritmus elemzi a múltbeli adatmintákat és egyéb speciális idősorokat. A Costa-ban a Dyntell mély előrejelzése körülbelül 90%-os pontosságú előrejelzést ad egy héttel előre.
2. Ana Pan
Az Ana Pan Európa egyik legnagyobb sütőüzeme, ahol a Dyntell prediktív és előíró elemzését használják az üzletek eladásának előrejelzésére, és ennek alapján a péksütemények gyártására. Az Ana Pannál a TimeNet korrelációs adatokat és a Deep Prediction szerver-klasztereket használják a gyártandó termékek számának és az adott boltba szállítandó termékek számának megjóslására. A Dyntell Bi rendszer automatikusan betölti az előre jelzett adatokat az Ana Pan ERP rendszerébe, ahol az előrejelzett mennyiségek közvetlenül a termelés- tervezési és gyártási modulokba kerülnek.
A predikciónak az élelmiszeriparban nagy jelentősége van a termékek szavatossági idejének köszönhetően, hiszen ha valaminek lejárt a szavatossága, akkor az jó eséllyel a kukába kerül, azaz a teljes önköltség csökkenti a várható profitot. Ilyen esetekben a predikció, ha csupán 1% -os pontossággal tud jobban jósolni, mint a menedzser, akkor egyenes arányban csökkentheti a hulladék mennyiségét. Ez az 1% akár ezer dolláros megtakarítást is jelenthet hetente. (Az Ana Pan nem járult hozzá előrejelzési hatékonysági számaik közzétételéhez.)
Önnél melyik előrejelzés működne a legjobban?
Abból induljon ki, hogy mennyire fontos Önnek, hogy előre lássa az üzleti adatai jövőjét. Ha lehetséges, próbálja meg kiszámítani a nyereséget, amit nyerhet, ha tudná, például a jövőbeni rendelései mennyiségét vagy az adott napon történő értékesítést egy adott boltban.
A következő kérdés a rendelkezésre álló üzleti adatok mennyiségétől függ. Ha a következő 12 hónapban szeretné tudni a cashflow-előrejelzést, és 3 éves múltbeli adatsora van, akkor valószínűleg ez nem elegendő a jó előrejelzéshez. Azonban ugyanez az adatmennyiség tökéletes lehet a jövő heti pénzügyi tranzakciók előrejelzésére. Mi történik abban az esetben, ha azt szeretné, hogy egy rendszer előrejelezze a jövő hét eladását egy adott termék esetében, és 30 évnyi adata van, de csak 10 értékesítése volt az adott termékből a 30 év alatt? Sajnos, ez is egy lehetetlen küldetés, bármilyen jó is az algoritmus, hiszen pont abból az adatból nemáll elegendő a rendelkezésre, amivel egy fő szempontként számolnánk.
Ha az idősorokban sok bizonytalanság van (pl. szabálytalan nagy árbevétel az értékesítésben), akkor először meg kell tisztítani az adatokat, és ezért jobb, ha az előrejelzésben beépített outlier szűrőket használ.
Az adatok korrelálnak más idősorokkal? A termék fő alapanyaga listázva van a tőzsdén? Kíváncsi, hogy az adatai mennyire függnek a gazdasági, földrajzi vagy Google keresési adatoktól? Ebben az esetben használjon nagy adattárakat, mint például a TimeNet.cloud, hogy ellenőrizze a korrelációkat.
Az önkiszolgáló használat a predikció felhasználásának kulcsfontosságú eleme. Ha nem matematikus vagy adatkutató, ne próbálja meg megtanulni a motorháztető alatt található komplex rendszereket. Ilyenkor egykattintásos funkcióra van szüksége.
2018 januárjában a Gartner felmérést adott ki a mesterséges intelligencia projektekről, ahol megállapították, hogy a felépített adatmodellek több mint 60% soha nem került felhasználásra. Ezért ha az előrejelzés stratégiai kérdés az Ön vállalkozásában, akkor szüksége van egy professzionális csapatra (belső vagy kiszervezett), amely segít a jó minőségű előrejelzés adatforrásainak és módszereinek beállításában és karbantartásában.